Highly available, robust access to critical IBM i applications and data
Reliability at a fraction of the cost
Rocket iCluster high availability/disaster recovery (HA/DR) solutions ensure uninterrupted operation for your IBM i applications, providing continuous access by monitoring, identifying, and self-correcting replication problems.
Confidence in your IBM i availability is paramount
Rocket iCluster reduces downtime related to unexpected IBM i system interruptions with real-time, fault-tolerant, object-level replication. In the event of an outage, you can bring a “warm” mirror of a clustered IBM i system into service within minutes.
iCluster disaster recovery software ensures a high-availability environment by giving business applications concurrent access to both master and replicated data. This setup allows you to offload critical business tasks such as running reports and queries as well as ETL, EDI, and web tasks from your secondary system without affecting primary system performance.
Proactive issue notifications and self-correction for replication problems help your team identify and address potential issues before they affect the system availability or recovery solution. The administrative capabilities in iCluster help staff easily configure and perform operations such as starting, ending, and switching replication groups, saving time and removing some of the risks associated with manual processes.
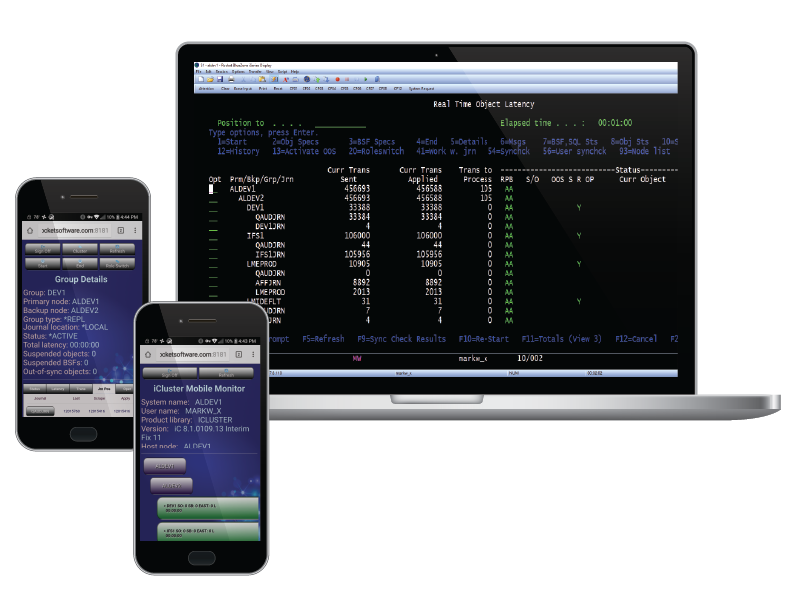
The intuitive, browser-agnostic web interface makes it easy for IT administrators to control the health of the replication. Users do not need IBM i domain expertise or command knowledge to effectively manage replications with our disaster recovery software.
The native cloud support of Rocket iCluster enables to offload workloads from the datacenter to the cloud to benefit from the flexibility and cost effectiveness that cloud offers for pure or hybrid cloud usage. Different geos for your production and the backup in the cloud increase the security in case of a disaster. Rocket iCluster is running seamlessly in Skytap and on IBM Cloud.